
はじめに
こんにちは、Pike8です。みなさんは競プロでテンプレートやスニペットは使っていますか。Pike8は主にVSCodeのスニペットを使っています。今回はPike8が何度か競プロに参加して更新してきたスニペットを紹介したいと思います。
テンプレート VS スニペット
競プロを始めたとき、テンプレートを使うかスニペットを使うかで悩みました。ここでいうテンプレートとは、以下のようによく使うマクロや定数、関数などを書いたファイルを事前に準備し、問題を解く際にコピーして使うというものです。
#include <bits/stdc++.h>
using namespace std;
// clang-format off
struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;
// clang-format on
#define REP(i, n) for (int i = 0; i < (int)(n); i++)
// Add more macro, constants or function here
int main() {
}一方スニペットは、VSCodeでは .vscode/.[任意の文字列].code-snippets に以下のようなJSONを追加し、エディタの補完機能でコードを補完していきます。IntelliJやCLionを使う場合は、ライブテンプレートという同様の機能を利用します。
{
"main": {
"body": [
"#include <bits/stdc++.h>",
"using namespace std;",
"",
"// clang-format off",
"struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;",
"// clang-format on",
"#define int long long",
"",
"int main() {",
" $0",
"}",
""
],
"prefix": "main"
},
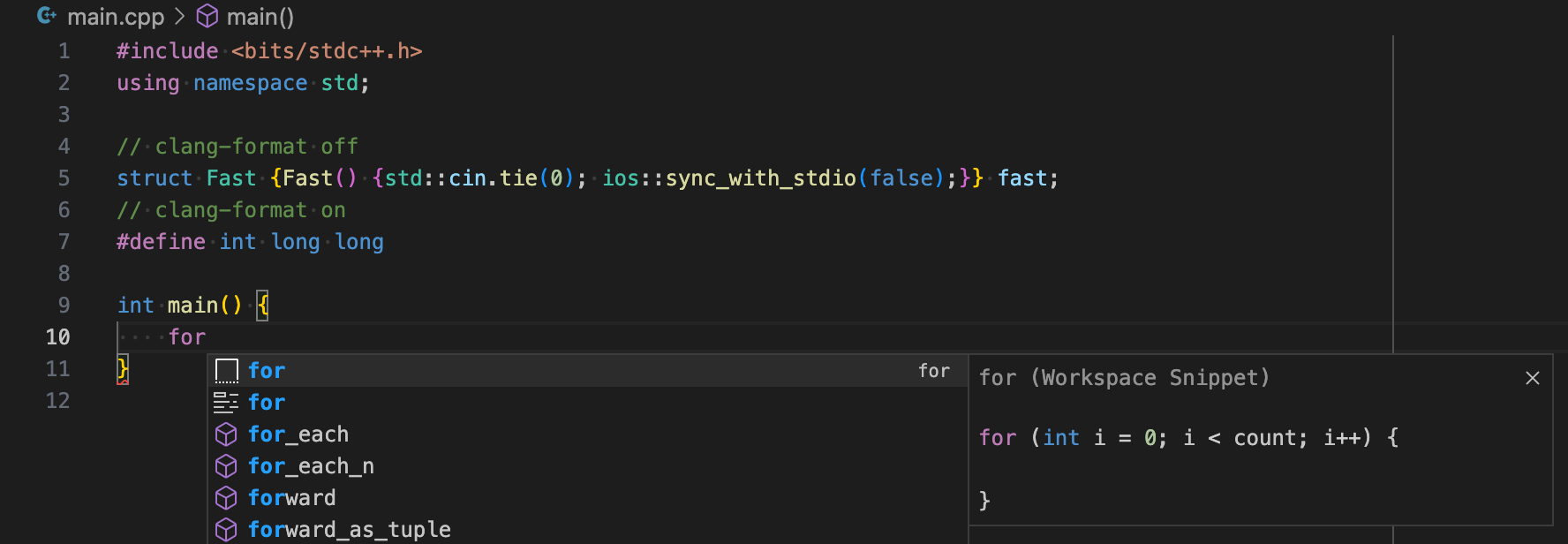
"for": {
"body": [
"for (int ${1:i} = ${2:0}; $1 < ${3:count}; $1++) {",
" $0",
"}"
],
"prefix": "for"
},
// Add more snippets here
}
テンプレートを使うメリットとして、環境を選ばないことがあります。個人のPCやエディタを使えないコンテストにも有効です。一方でスニペットを使うメリットは、ファイルから使わないコードを省くことができ、その結果、かなり気軽に新たなスニペットを追加できます。またマクロを使わなくてよいため、コードを読む際の可読性も高いです。Pike8はAtCoderをメインとして競プロに参加しており、前者にあまりメリットを感じなかったため、現在はテンプレートではなくスニペットを利用しています。
スニペット
Pike8がAtCoderで使用している.code-snippetsファイルはこちらになります。以下にこのファイルで定義されているスニペットを紹介します。
コード中に全て大文字で書かれている単語は、スニペットにより補完したときに順次カーソルがフォーカスし、容易に変更することができます。
main関数
// "main"
#include <bits/stdc++.h>
using namespace std;
// clang-format off
struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;
// clang-format on
#define int long long
signed main() {
}main関数と毎回追加するinclude文などを補完します。また、Pike8は int を long long として扱うようにしています。これには賛否両論あり、Pike8も長く使わないようにしていたのですが、忘れたころに起こる int のオーバーフローによるWAを避けるために今は取り入れています。ただしこの場合でも、atoll を使うべきところで atoi を使ったり、accumulate の初期値に 0LL を渡すべきところで 0 を渡したりするとオーバーフローが起きるので注意が必要です。
入力
// "ci"
TYPE IN;
cin >> IN;
// "ci2" ~ "ci5"
TYPE IN1, IN2;
cin >> IN1 >> IN2;
// "civec"
vector<TYPE> VEC(SIZE);
for (auto &&in : VEC) {
cin >> in;
}
// "civec2"
vector<vector<TYPE>> VEC(SIZE1, vector<TYPE>(SIZE2));
for (auto &&row : VEC) {
for (auto &&in : row) {
cin >> in;
}
}civec 、civec2 は標準入力を vector に読み込む際に使います。
出力
// "co"
cout << OUT << '\n';
// "co2" ~ "co5"
cout << OUT1 << OUT2 << '\n';
// "covec"
for (auto out = VEC.begin(); out != VEC.end(); out++) {
cout << *OUT << (out != --VEC.end() ? ' ' : '\n');
}
// "covec2"
for (auto &&row : VEC) {
for (auto out = row.begin(); out != row.end(); out++) {
cout << *OUT << (out != --row.end() ? ' ' : '\n');
}
}
// "coyesno"
cout << (CONDITION ? "Yes" : "No") << '\n';
// "coaccuracy"
cout << fixed << setprecision(12);
// "cobool"
cout << boolalpha;
// "copad"
cout << setfill('0') << setw(LENGTH) << OUT << '\n';covec 、covec2 は vector を書き出す際に使います。coyesno は条件により Yes か No を出力します。補完時に実際に出力する文字の形式を選ぶことができます。

タイプ
// "ll"
long long
// "vec"
vector<TYPE>
// "vec2", "vec3"
vector<vector<TYPE>>
// "set", "umap"
set<TYPE>
// "uset", "umap"
unordered_set<TYPE>
// "usetcustom", "umapcustom"
unordered_set<TYPE, TYPE::Hash>
// "pq"
priority_queue<TYPE>
// "pqreverse"
priority_queue<TYPE, vector<TYPE>, greater<TYPE>>多次元 vector や unordered_set など、長いタイプを補完します。usetcustom と umapcustom は、自分で定義した構造体を unordered_set や unordered_map の要素にするときに使います。Hash などを定義した構造体はこちらのスニペットで補完できます。
変数宣言
// "vecsized"
vector<TYPE> NAME(SIZE);
// "vec2sized", "vec3sized"
vector<vector<TYPE>> NAME(SIZE1, vector<TYPE>(SIZE2));
// "pqlambda"
priority_queue<TYPE, vector<TYPE>, function<bool(TYPE, TYPE)>> NAME([&](TYPE VALUE1, TYPE VALUE2) { });vecsized はサイズを指定した vector の宣言です。多次元 vector になると TYPE の指定が重複するので一度に入力できると便利です。pqlambda は、比較可能ではない構造体を TYPE に指定し、比較方法をラムダで指定するときに利用します。
構造体
// "struct2", "struct3"
template <class Type> inline void hash_combine(size_t &h, const Type &value) noexcept {
size_t k = hash<Type>{}(value);
uint64_t m = 0xc6a4a7935bd1e995;
int r = 47;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
h += 0xe6546b64;
}
struct NAME {
TYPE1 VALUE1;
TYPE2 VALUE2;
string to_string() const {
ostringstream oss;
oss << "NAME(VALUE1=" << VALUE1 << ", VALUE2=" << VALUE2 << ")";
return oss.str();
}
bool operator==(const NAME &other) const {
return tie(VALUE1, VALUE2) == tie(other.VALUE1, other.VALUE2);
}
bool operator<(const NAME &other) const {
return make_pair(VALUE1, VALUE2) < make_pair(other.VALUE1, other.VALUE2);
}
struct Hash {
size_t operator()(const NAME &p) const noexcept {
size_t seed = 0;
hash_combine(seed, p.VALUE1);
hash_combine(seed, p.VALUE2);
return seed;
}
};
};要素を2つ、ないし3つ持つ構造体のためのスニペットです。set や map で利用するために operator< をオーバーロードしています。また、unordered_set や unordered_map で利用するために Hash 構造体を定義しています。pair や tuple では要素のアクセスにミスが起こりやすいので、Pike8はできるだけこちらのスニペットで構造体を定義しています。
定数
// "infi"
const int INF = 1e9;
// "infll"
const long long INF = 1e18;
// "dxdy"
const vector<int> DX = {1, 0, -1, 0};
const vector<int> DY = {0, 1, 0, -1};
// "drowdcol"
const vector<int> DROW = {1, 0, -1, 0};
const vector<int> DCOL = {0, 1, 0, -1};dxdy と drowdcol は座標平面や二次元 vector の前後左右を走査する際に利用しています。
ループ
// "for"
for (int I = 0; I < COUNT; I++) {
}
// "forreverse"
for (int I = COUNT - 1; I >= 0; I--) {
}
// "forrange"
for (auto &&ELEMENT : VEC) {
}通常のfor文、デクリメントするfor文、範囲for文を書くためのスニペットです。
頻度が高いコード
// "lf"
'\n'
// "lforspace"
(CONDITION ? ' ' : '\n')
// "all", "allreverse"
VEC.begin(), VEC.end()
// "chmax", "chmin"
MAX = max(MAX, TARGET);
// "rangeexclusive", "rangeinclusive"
MIN <= VALUE && VALUE < MAXlforspace は vector を出力する際などにたまに利用します。all 、allreverse は sort や accumulate など vector を引数として渡すときに利用します。chmax 、chmin は計算結果が現在の値よりも大きかったり、小さかったりしたときに限り現在の値を更新する場合に利用します。rangeexclusive 、rangeinclusiveは二次元配列の走査などでインデックスが配列の範囲内に収まっているかをチェックするときなどに利用します。
間違いやすいコード
// "popcount"
__builtin_popcount(VALUE)__builtin_popcount は数値のビットが1になっている個数を返します。bit というヘッダファイルに似た名前で __popcount という関数が定義されています。一度、bit をインクルードせずに __popcount を使ってWAになって以降、こちらのスニペットを利用しています。
関数とラムダ
// "fun"
function<RET(TYPE)> NAME = [&](TYPE VALUE) {
};
// "fun2"
function<RET(TYPE1, TYPE2)> NAME = [&](TYPE1 VALUE1, TYPE2 VALUE2) {
};
// "lambda"
[&](AUTO const &VALUE) { }
// "lambda2"
[&](AUTO1 const &VALUE1, AUTO2 const &VALUE2) { }fun 、fun2 は関数の中でローカル関数を定義したいときに利用します。DFSなど再帰関数を定義するときに便利です。lambda 、lamda2 は sort や accumulate などに渡したいときに利用します。すべてクロージャに & を指定しているので、どのスコープ内の変数にもアクセスできます。競プロで書くコードならスコープを気にしなくてもそこまで問題はないと思います。
コレクション操作
// "filter"
vector<TYPE> FILTERED;
copy_if(VEC.begin(), VEC.end(), back_inserter(FILTERED), [&](TYPE const &value) { });
// "transform"
vector<TYPE> TRANSFORMED;
transform(VEC.begin(), VEC.end(), back_inserter(TRANSFORMED), [&](AUTO const &value) { });
// "partialsum"
vector<TYPE> SUMS = {0};
partial_sum(VEC.begin(), VEC.end(), back_insert_iterator(SUMS));よく使うコレクションに対する操作です。transform はいわゆるmap処理です。partialsum は累積和を求めるのに利用します。
アルゴリズム
二分探索
// "binarysearch"
auto isOk = [&](TYPE mid) {
};
TYPE ok = OKBOUND;
TYPE ng = NGBOUND;
while (abs(ok - ng) > 1) {
type mid = (ok + ng) / 2;
if (isOk(mid)) {
ok = mid;
} else {
ng = mid;
}
}いわゆるめぐる式二分探索を補完します。
文字列変換
// itos
string itos(long long value, int radix) {
if (value == 0) {
return "0";
}
string res;
bool isNegative = value < 0;
value = abs(value);
while (value > 0) {
int r = value % radix;
char c = r <= 9 ? r + '0' : r - 10 + 'a';
res = c + res;
value /= radix;
}
if (isNegative) {
res = '-' + res;
}
return res;
}数値を文字列に変換する関数を補完します。std::to_string では基数を指定できないので、基数の指定が必要なときに利用します。
繰り返し二乗法
// "powll"
long long powll(long long base, long long exponent) {
long long ret = 1;
long long remain = exponent;
while (remain > 0) {
if (remain % 2 == 1) {
ret *= base;
}
base *= base;
remain /= 2;
}
return ret;
}繰り返し二乗法で累乗を計算する関数を補完します。競プロでは累乗をある数で割った余りを求めることも多いのですが、こちらの関数では剰余は行っていません。剰余を求める場合は、AtCoderでは Modint の pow 関数を使うとよいでしょう。
素数
// "prime"
bool is_prime(long long n) {
if (n == 1) {
return false;
}
for (long long i = 2; i * i <= n; i++) {
if (n % i == 0) {
return false;
}
}
return true;
}
// "primefact"
vector<long long> get_prime_factorization(long long n) {
vector<long long> ret;
long long remain = n;
for (long long i = 2; i * i <= remain; i++) {
while (remain % i == 0) {
ret.push_back(i);
remain /= i;
}
}
if (remain != 1) {
ret.push_back(remain);
}
return ret;
}prime は素数を判定するための関数を補完します。primefact は素因数分解を行う関数を補完します。
順列、組み合わせ
// "permutation"
void foreach_permutation(vector<TYPE> list, function<void(vector<TYPE>)> callback) {
vector<TYPE> permutation(list.size());
vector<int> indexes(list.size());
iota(indexes.begin(), indexes.end(), 0);
do {
for (int i = 0; i < indexes.size(); i++) {
permutation[i] = list[indexes[i]];
}
callback(permutation);
} while (next_permutation(indexes.begin(), indexes.end()));
}
// "permutation2"
void foreach_permutation(vector<TYPE> list, int count, function<void(vector<TYPE>)> callback) {
vector<TYPE> permutation(count);
vector<TYPE> combination(count);
vector<int> indexes(count);
iota(indexes.begin(), indexes.end(), 0);
function<void(int, int)> dfs = [&](int position, int index) {
if (position == count) {
do {
for (int i = 0; i < indexes.size(); i++) {
permutation[i] = combination[indexes[i]];
}
callback(permutation);
} while (next_permutation(indexes.begin(), indexes.end()));
return;
}
for (int i = index; i < list.size(); i++) {
combination[position] = list[i];
dfs(position + 1, i + 1);
}
};
dfs(0, 0);
}
// "combination"
void foreach_combination(vector<type> list, int count, function<void(vector<type>)> callback) {
vector<type> combination(count);
function<void(int, int)> dfs = [&](int position, int index) {
if (position == count) {
callback(combination);
return;
}
for (int i = index; i < list.size(); i++) {
combination[position] = list[i];
dfs(position + 1, i + 1);
}
};
dfs(0, 0);
}permutation は渡した list パラメータの順列に対して、ラムダ式で処理するための関数を補完します。permutation2 はそれに加えて、取り出す要素の個数を指定できるようにしています。combination は 渡した list パラメータから count 個取り出した組み合わせをラムダ式で処理するための関数を補完します。それぞれ、\(_nP_n\)、\(_nP_k\)、\(_nC_k \)に対応します。
AtCoder Library
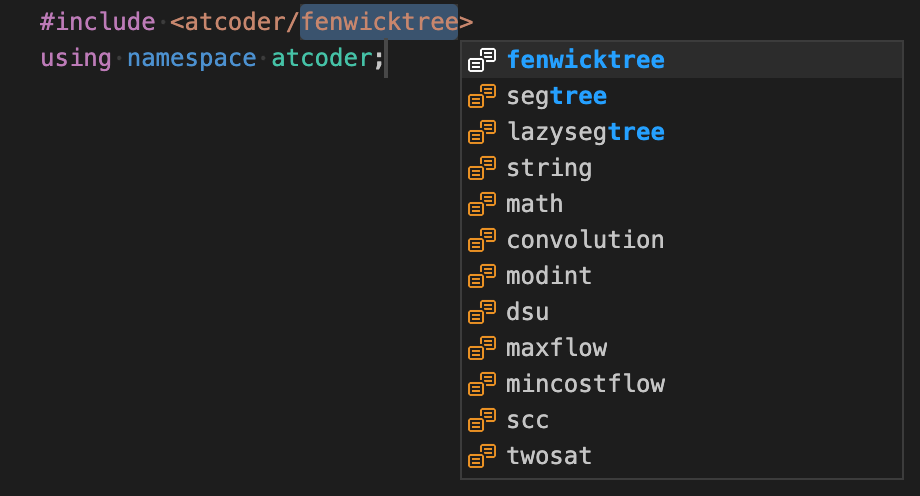
// "acl"
#include <atcoder/FENWICKTREE>
using namespace atcoder;
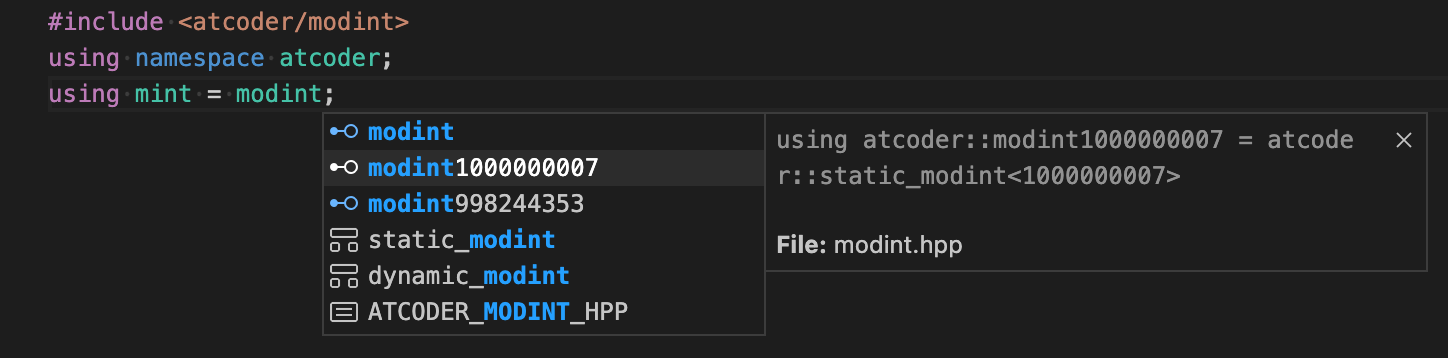
// "mint"
using mint = modint;AtCoder Library用のスニペットです。acl はヘッダのインクルードに利用します。atcoder/all をインクルードするとコンパイル時間に影響しそうだったので、補完時にどのヘッダをインクルードするか選べるようにしています。
mint はAtCoder Libraryの中でもよく使う modint の atcoder::modint1000000007 と atcoder::modint998244353 が長いので、それらを別名 mint で定義するために利用します。
所感
まとめてみるとかなり多くなっていました。C++はコレクションに対する操作など、どうしてもほかの言語と比べてコードが冗長になることが多いですが、テンプレートやスニペットを使ってコーディングの時短をしていきたいです。そして.code-snippetsはこれからもどんどん更新していきたいです。
